Designing scalable, reliable systems isn’t just about writing code or picking the right tools. It’s about making thoughtful decisions at every layer of the architecture—from the initial idea to detailed class structures.
In this second part of the System Design Deep Dive series, we’ll walk through the four critical pillars of practical system design:
- Asking Clarifying Questions – Define the problem before you solve it.
- Back-of-the-Envelope Estimation – Will your system scale under expected load?
- High-Level Design (HLD) – What are the core components and how do they interact?
- Low-Level Design (LLD) – What do the data models, classes, and interfaces look like?
Then, we'll apply these principles to design a real-world system: A Distributed Caching System.
Contents
Asking Clarifying Questions
Before you dive into diagrams or code, ask questions. This step is often overlooked, but it's where the problem space gets clearly defined. You’ll uncover constraints, expectations, and usage patterns.
Key Clarification Areas
- Who are the users?
- What scale are we expecting? (Daily traffic, data size)
- What consistency and latency requirements do we have?
- What are the availability/uptime expectations?
- Are there any tech stack restrictions?
Tip: Clarifying questions avoid overengineering and ensure your design solves the actual problem—not just the one you imagined.
Back-of-the-Envelope Estimation
Once the requirements are clear, the next step is estimating scale and resource needs. These rough numbers help guide architecture decisions early.
Estimate for
- Daily active users (DAU)
- Requests/Queries per second (R/QPS)
- Data size
- Bandwidth
- Storage
- Read/Write ratios
Tip: Use real-world examples or assumptions (e.g., Redis object overhead, network latencies) to guide you.
High-Level Design (HLD)
High-Level Design focuses on macro-architecture: components, protocols, and how they interact. You're answering "What are the parts?" and "How do they communicate?"
HLD Must Include
- Core components and responsibilities
- Data flow between components
- Communication patterns (REST, gRPC, Kafka, etc.)
- Scalability and fault tolerance
- Caching, logging, monitoring
Tip: Always show how your system scales (e.g., using consistent hashing, sharding).
Low-Level Design (LLD)
Low-Level Design zooms into classes, interfaces, database schemas, and how each part is implemented.
LLD Must Include
- Class and method structures
- Interface definitions
- Data structures and models
- Database schema (if applicable)
- Error handling and edge cases
- Caching logic (e.g., TTL, eviction)
- Performance optimizations
Tip: Don’t go into full-blown implementation unless asked—just provide key interfaces, relationships, and data flows.
Example: Designing a Distributed Caching System
Imagine you're asked to design a Distributed Caching System like Redis or Memcached — something that can scale, serve high throughput, and tolerate failures.
Clarifying Requirements
Before jumping into design, clarify the following:
- Is the cache write-through or write-back?
- Is it for session data, database acceleration, or static asset caching?
- What are the consistency guarantees? Can we tolerate stale data?
- Is eviction required (e.g., LRU, LFU)?
Should the cache be distributed across data centers?
These questions define your design boundaries, like consistency vs availability or speed vs durability.
Estimating System Load
Let’s estimate for a caching system used to serve product data on an e-commerce platform.
| Metric | Estimate |
|---|---|
| Number of daily users | 10 million |
| Avg requests per user/day | 50 |
| Total requests per day | 500 million |
| Peak QPS (5x avg) | ~30,000 QPS |
| Avg response size | 5 KB |
| Daily data transfer | ~2.5 TB |
| Cache size (100M items avg) | 100M * 5 KB = ~500 GB |
| Cache hit ratio | 90% (read-heavy system) |
| Expected latency per read | < 10ms |
These estimations play a critical role in shaping key design decisions—such as selecting the right in-memory caching technology (e.g., Redis, Memcached), determining optimal memory allocation per node, designing an effective sharding and replication strategy, and choosing appropriate eviction policies—to ensure the cache is fast, scalable, and fault-tolerant under real-world load.
High-Level Architecture
Components Overview
| Component | Description |
|---|---|
| Clients | API servers or services needing fast key-based lookup |
| Load Balancer | Distributes cache requests across nodes |
| Cache Nodes | In-memory key-value storage with TTL and eviction |
| Hashing Layer | Routes keys consistently to the correct node |
| Persistent Storage (Optional) | Fallback for cache misses (e.g., database) |
| Replication/Cluster Management | Keeps data highly available |
Sample Data Flow (Read Path)
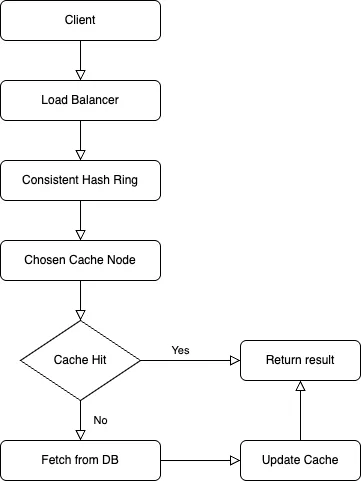
Key Architectural Decisions
1. Consistent Hashing
Ensures minimal key movement when nodes are added/removed.
Example: Key
"user:123"is hashed and mapped to node A. If node A goes down, consistent hashing minimizes reshuffling — only a small subset of keys need to be re-mapped.
2. Replication (Optional)
To ensure high availability, cache nodes may replicate data to a backup node.
3. Eviction Policy
Define how stale data is evicted. Common: LRU, LFU, TTL-based.
4. Asynchronous Writes
For write-through cache: write to DB and cache simultaneously.
For write-behind (write-back): write to cache first, persist to DB later asynchronously.
High-Level Architecture Diagram
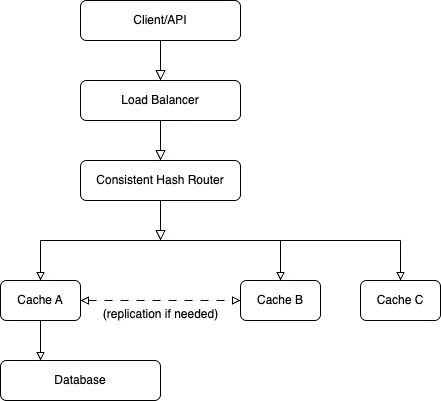
Low-Level Implementation
Let’s walk through a simplified Java-based design of a distributed in-memory cache node:
Core Interfaces and Classes
Cache Interface
public interface Cache {
String get(String key);
void put(String key, String value, long ttlMillis);
void delete(String key);
}CacheEntry with TTL Support
public class CacheEntry {
String value;
long expiryTime;
public CacheEntry(String value, long ttlMillis) {
this.value = value;
this.expiryTime = System.currentTimeMillis() + ttlMillis;
}
public boolean isExpired() {
return System.currentTimeMillis() > expiryTime;
}
}In-Memory Cache Implementation (With TTL + LRU)
public class LRUCache implements Cache {
private final int capacity;
private final Map<String, CacheEntry> cache;
public LRUCache(int capacity) {
this.capacity = capacity;
this.cache = new LinkedHashMap<>(capacity, 0.75f, true) {
protected boolean removeEldestEntry(Map.Entry<String, CacheEntry> eldest) {
return size() > LRUCache.this.capacity;
}
};
}
public synchronized String get(String key) {
CacheEntry entry = cache.get(key);
if (entry == null || entry.isExpired()) {
cache.remove(key);
return null;
}
return entry.value;
}
public synchronized void put(String key, String value, long ttlMillis) {
cache.put(key, new CacheEntry(value, ttlMillis));
}
public synchronized void delete(String key) {
cache.remove(key);
}
}Consistent Hashing Router
public class ConsistentHashRouter {
private TreeMap<Integer, Cache> ring = new TreeMap<>();
private List<Cache> nodes;
public ConsistentHashRouter(List<Cache> nodes) {
this.nodes = nodes;
for (Cache node : nodes) {
int hash = node.hashCode();
ring.put(hash, node);
}
}
public Cache getNode(String key) {
int hash = key.hashCode();
SortedMap<Integer, Cache> tail = ring.tailMap(hash);
if (!tail.isEmpty()) return tail.get(tail.firstKey());
return ring.firstEntry().getValue();
}
}Database Fallback (Optional)
public class CacheWithDBFallback implements Cache {
private final Cache localCache;
private final DatabaseClient db;
public CacheWithDBFallback(Cache localCache, DatabaseClient db) {
this.localCache = localCache;
this.db = db;
}
@Override
public String get(String key) {
String value = localCache.get(key);
if (value == null) {
value = db.get(key);
if (value != null) {
localCache.put(key, value, 60_000); // cache for 1 min
}
}
return value;
}
@Override
public void put(String key, String value, long ttlMillis) {
db.put(key, value);
localCache.put(key, value, ttlMillis);
}
@Override
public void delete(String key) {
db.delete(key);
localCache.delete(key);
}
}Other LLD Considerations
| Aspect | Detail |
|---|---|
| Thread Safety | Use ConcurrentHashMap or proper synchronization |
| Monitoring | Track hit/miss ratio, TTL expirations |
| Health Checks | Each node exposes heartbeat APIs |
| Serialization | If objects need to be cached (e.g., User), use JSON/protobuf |
| Eviction Metrics | Log evictions for tuning |
| Security | If multi-tenant, isolate keys by namespace/user ID |
Final Thoughts
Whether you're designing a distributed cache, notification system, or message broker, the same four pillars apply:
- Clarify the Problem
- Estimate the Load
- Architect at a High Level
- Detail the Code with LLD
By combining these systematically, you make architectural decisions that are informed, scalable, and explainable—critical for interviews and real-world systems alike.
In the next part of this series, we’ll explore core infrastructure components like CDNs, Bloom Filters, Distributed Caching, and Database Sharding that power scalable systems at global scale.
📌 Enjoyed this post? Bookmark it and drop a comment below — your feedback helps keep the content insightful and relevant!